








DeepSeek's new aI Model Appears to be among the Best 'open&#…
페이지 정보
Judi 작성일25-01-31 19:07본문
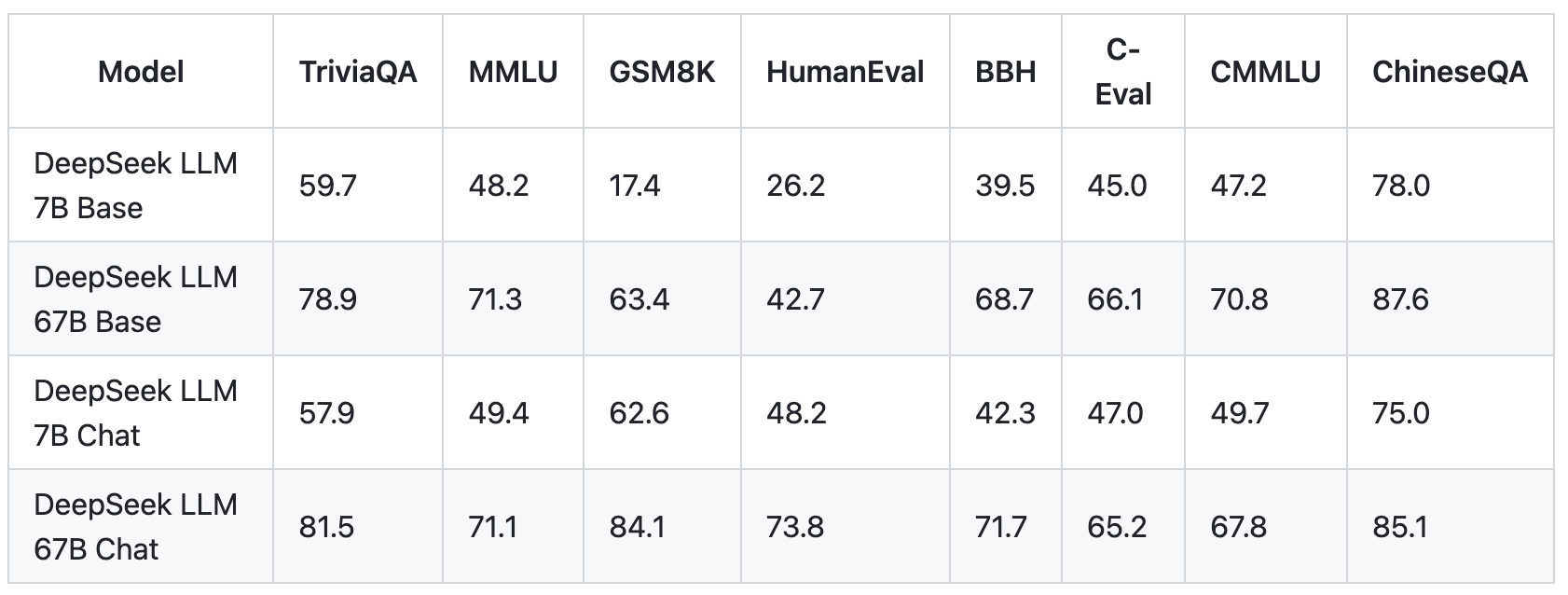
I believe this speaks to a bubble on the one hand as every government goes to want to advocate for extra investment now, however issues like DeepSeek v3 additionally points towards radically cheaper training in the future. Its expansive dataset, meticulous training methodology, and unparalleled efficiency across coding, mathematics, and language comprehension make it a stand out. A standout feature of DeepSeek LLM 67B Chat is its remarkable performance in coding, achieving a HumanEval Pass@1 score of 73.78. The model additionally exhibits distinctive mathematical capabilities, with GSM8K zero-shot scoring at 84.1 and Math 0-shot at 32.6. Notably, it showcases a powerful generalization skill, evidenced by an outstanding rating of 65 on the challenging Hungarian National Highschool Exam. The Hungarian National Highschool Exam serves as a litmus take a look at for mathematical capabilities. This helped mitigate data contamination and catering to specific take a look at units. Fine-tuning refers back to the means of taking a pretrained AI model, which has already learned generalizable patterns and representations from a larger dataset, and additional training it on a smaller, more specific dataset to adapt the mannequin for a particular process.
 The increased power effectivity afforded by APT can also be significantly important within the context of the mounting vitality costs for coaching and operating LLMs. Efficient coaching of massive fashions demands high-bandwidth communication, low latency, and fast knowledge transfer between chips for each forward passes (propagating activations) and backward passes (gradient descent). Current large language fashions (LLMs) have more than 1 trillion parameters, requiring a number of computing operations throughout tens of thousands of high-performance chips inside a knowledge middle. Ollama lets us run large language models domestically, it comes with a reasonably easy with a docker-like cli interface to start, stop, pull and list processes. Continue comes with an @codebase context provider built-in, which helps you to mechanically retrieve the most relevant snippets out of your codebase. Recently, Alibaba, the chinese language tech big additionally unveiled its own LLM known as Qwen-72B, which has been skilled on excessive-quality data consisting of 3T tokens and in addition an expanded context window size of 32K. Not simply that, the company additionally added a smaller language model, Qwen-1.8B, touting it as a present to the research group. As we look forward, the impact of DeepSeek LLM on research and language understanding will shape the future of AI. Trained meticulously from scratch on an expansive dataset of two trillion tokens in each English and Chinese, the DeepSeek LLM has set new standards for research collaboration by open-sourcing its 7B/67B Base and 7B/67B Chat versions.
The increased power effectivity afforded by APT can also be significantly important within the context of the mounting vitality costs for coaching and operating LLMs. Efficient coaching of massive fashions demands high-bandwidth communication, low latency, and fast knowledge transfer between chips for each forward passes (propagating activations) and backward passes (gradient descent). Current large language fashions (LLMs) have more than 1 trillion parameters, requiring a number of computing operations throughout tens of thousands of high-performance chips inside a knowledge middle. Ollama lets us run large language models domestically, it comes with a reasonably easy with a docker-like cli interface to start, stop, pull and list processes. Continue comes with an @codebase context provider built-in, which helps you to mechanically retrieve the most relevant snippets out of your codebase. Recently, Alibaba, the chinese language tech big additionally unveiled its own LLM known as Qwen-72B, which has been skilled on excessive-quality data consisting of 3T tokens and in addition an expanded context window size of 32K. Not simply that, the company additionally added a smaller language model, Qwen-1.8B, touting it as a present to the research group. As we look forward, the impact of DeepSeek LLM on research and language understanding will shape the future of AI. Trained meticulously from scratch on an expansive dataset of two trillion tokens in each English and Chinese, the DeepSeek LLM has set new standards for research collaboration by open-sourcing its 7B/67B Base and 7B/67B Chat versions.
If your machine can’t handle each at the same time, then attempt each of them and resolve whether or not you prefer a local autocomplete or a neighborhood chat expertise. The model structure is essentially the same as V2. Chinese corporations creating the same applied sciences. Chinese corporations creating the troika of "force-multiplier" technologies: (1) semiconductors and microelectronics, (2) synthetic intelligence (AI), and (3) quantum data applied sciences. The notifications required below the OISM will name for corporations to provide detailed details about their investments in China, offering a dynamic, excessive-decision snapshot of the Chinese investment panorama. While U.S. companies have been barred from promoting sensitive applied sciences on to China underneath Department of Commerce export controls, U.S. The diminished distance between components implies that electrical alerts need to journey a shorter distance (i.e., shorter interconnects), while the higher purposeful density permits elevated bandwidth communication between chips due to the greater variety of parallel communication channels accessible per unit area. Regardless of the case could also be, builders have taken to DeepSeek’s fashions, which aren’t open source because the phrase is commonly understood however are available under permissive licenses that enable for business use.
In response, the Italian knowledge safety authority is in search of additional information on DeepSeek's assortment and use of private knowledge and the United States National Security Council announced that it had began a nationwide security evaluation. These prohibitions intention at apparent and direct nationwide security considerations. In sure instances, it is focused, prohibiting investments in AI systems or quantum technologies explicitly designed for navy, intelligence, cyber, or mass-surveillance finish makes use of, which are commensurate with demonstrable nationwide security considerations. Broadly, the outbound funding screening mechanism (OISM) is an effort scoped to focus on transactions that improve the military, intelligence, surveillance, or cyber-enabled capabilities of China. It not solely fills a coverage hole however units up a data flywheel that could introduce complementary effects with adjacent tools, such as export controls and inbound funding screening. Current semiconductor export controls have largely fixated on obstructing China’s access and capacity to supply chips at the most superior nodes-as seen by restrictions on high-efficiency chips, EDA tools, and EUV lithography machines-mirror this thinking.
In case you cherished this article and also you would want to obtain more details concerning ديب سيك generously visit the web-page.
댓글목록
등록된 댓글이 없습니다.






